kubernetes快速入门(中)
本文是《Kubernetes(k8s)快速入门》系列的中篇,延续了上篇的内容,旨在通过一个具体的微服务Demo项目,手把手地引导读者掌握Kubernetes的核心实践操作。文章以“app”和“app-gateway”两个无状态服务(即:微服务中的单个模块,区别于K8s Service)为例,详细讲解了从代码编译、镜像制作到K8s集群部署、配置管理、服务发现及优雅终止的完整流程。Demo项目代码,见https://github.com/Qinch/k8s-manifests/tree/master
0 Minikube工具简介
- 在(深入Kubernetes:从零开始的进阶之路(上))以及本文中,我们都是采用minikube工具在个人机器启动K8s集群。
- Minikube是一个构建本地K8s集群的工具,专注于让学习和开发 Kubernetes 变得容易。为了运行我们本文中的demo项目,我们只需要通过执行minikube start命令就可以在个人机器上启动K8s集群。Minikube的安装以及用法,见https://minikube.cn/docs/start 。
1 Demo项目简介
- 本文中的微服务demo项目,包含网关服务 app-gateway 和业务服务 app,两个组件均为无状态服务(即:服务本身不本地持久化运行数据与会话信息),相关的代码见 https://github.com/Qinch/k8s-manifests/tree/master/part2。
- Demo项目的请求链路:
- 外部客户端 → app-gateway(转发) → app服务(业务)
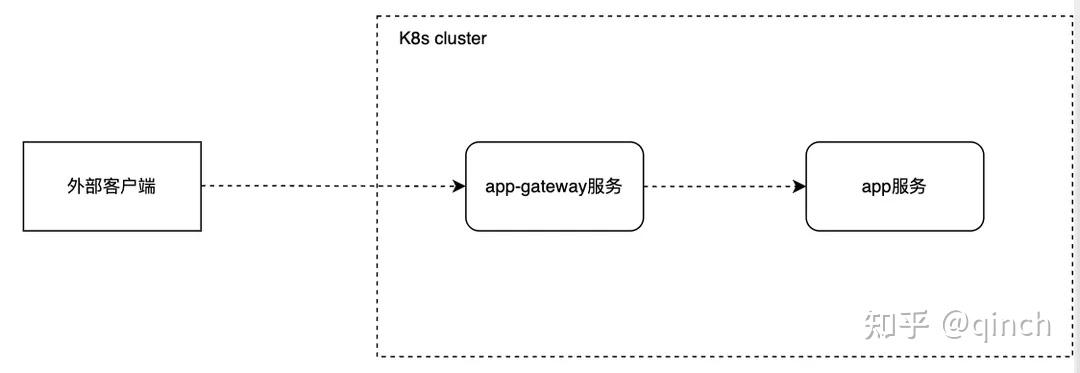
- 外部客户端 → app-gateway(转发) → app服务(业务)
1.1 Demo构建
- 我们以demo项目中的app服务的代码为例,先看一下其目录结构(注:编译相关脚本在./build目录):
ubuntu@VM-0-15-ubuntu:~/k8s-manifests/part2/app$ tree -L 2
.
├── build // 编译相关脚本
│ ├── build.sh // go build
│ ├── image.sh // docker build
│ └── kustomize.sh // kustomize build
├── cmd
│ └── main.go
├── configs // app-conf镜像相关
│ ├── Dockerfile // 用于制作app-conf镜像
│ └── sparse.txt
├── deployments // K8s manifests
│ ├── base
│ ├── manifests
│ └── overlays
├── Dockerfile // 用于制作app镜像
├── go.mod
├── go.sum
├── internal
│ └── service
├── Makefile // make 入口
├── target // go build的结构
│ └── bin
└── vendor // 省略展示
- 以test环境为例,我们先大概来看下app服务在个人机器上怎么进行代码编译/docker镜像制作,以及k8s manifest生成。
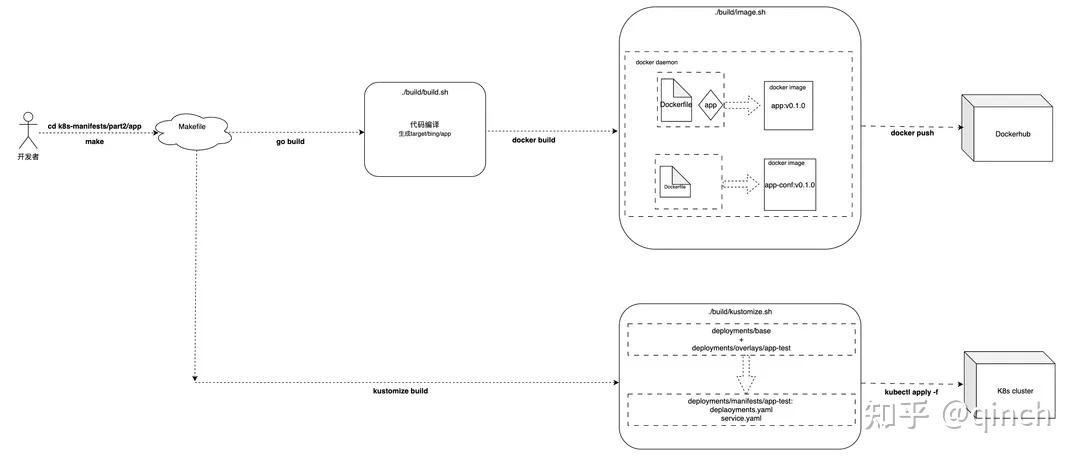
- 1 生成docker镜像
- 1.1 go build 代码编译
- 1.2 docker build生成docker镜像(注:在app项目中生成两个docker镜像,其中一个是app镜像,另一个是app-conf镜像, 详见第4节)。
- 2 生成k8s manifests
- 2.1 kustomize build生成k8s manifests
- 3 执行命令: make DOCKER_USER=qinchaowhut DOCKER_PWD=Dockerhub密码 VERSION=v0.1.1
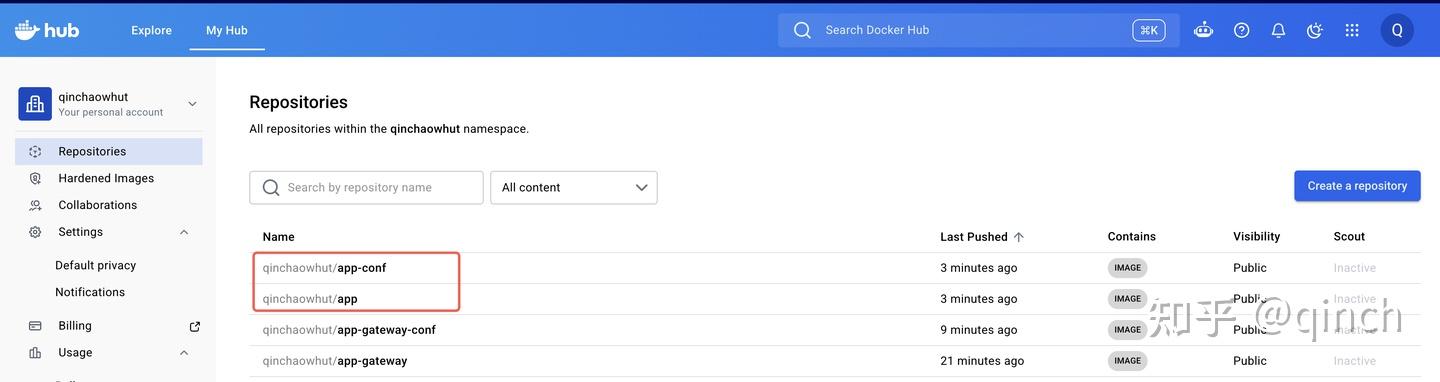
- 3.1 在Dockerhub中查看生成的镜像:
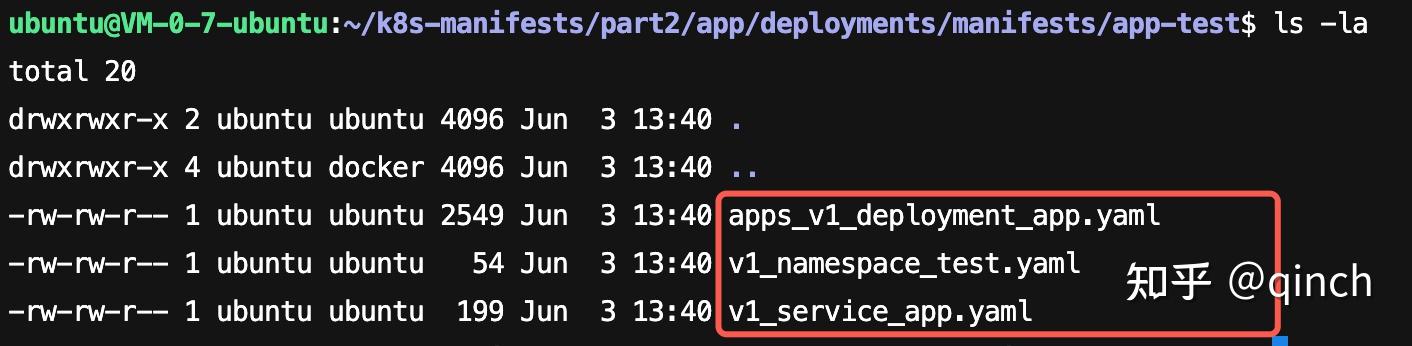
- 3.2 在./app/deployments/manifests目录查看生成的k8s配置清单:
- 3.1 在Dockerhub中查看生成的镜像:
- 1 生成docker镜像
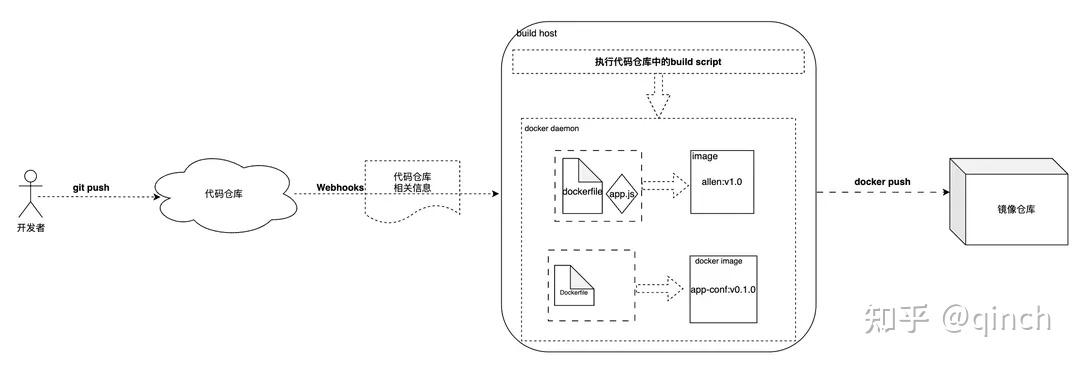
- 在实际项目中,docker镜像的大概制作流程:
 到这里,我们已经对demo项目进行了简单介绍,接下来我们将对其进行详细的介绍。
到这里,我们已经对demo项目进行了简单介绍,接下来我们将对其进行详细的介绍。
2 Namespace
- 以app服务为例,在实际的团队开发过程中,可能有多人需要同时在同一个K8s集群(比如 test集群)中对自己的app服务进行代码修改/测试,这时候如果所有人都部署app到该集群就会报错,因为在同一个K8s集群中Deployment的名字存在重复(Deployment的名字都是app,我们不可能给每个人分配一个独立的K8s集群)。或者是我们为了降低成本,希望将test和prod环境的app服务都部署在同一个k8s集群中,这时候将test和prod的app服务部署到同一K8s集群,会产生同样的报错。
- 此时,我们可以通过Namespace(类似于golang中的package, 不同的package 可以定义相同名字的function)来对同一个K8s集群中的资源(比如 Deployment,Service, Pod等)进行分组,从而划分为相互隔离的组(即:两个不同的Namespace中可以包含相同名字的资源)。
- 当然在实际项目中,可以将test和prod环境分别部署到不同的K8s集群,从而做到物理隔离。在dev环境中根据Namespace隔离,多人可以同时在同一个K8s集群中部署自己的业务服务。
2.1 创建Namespace
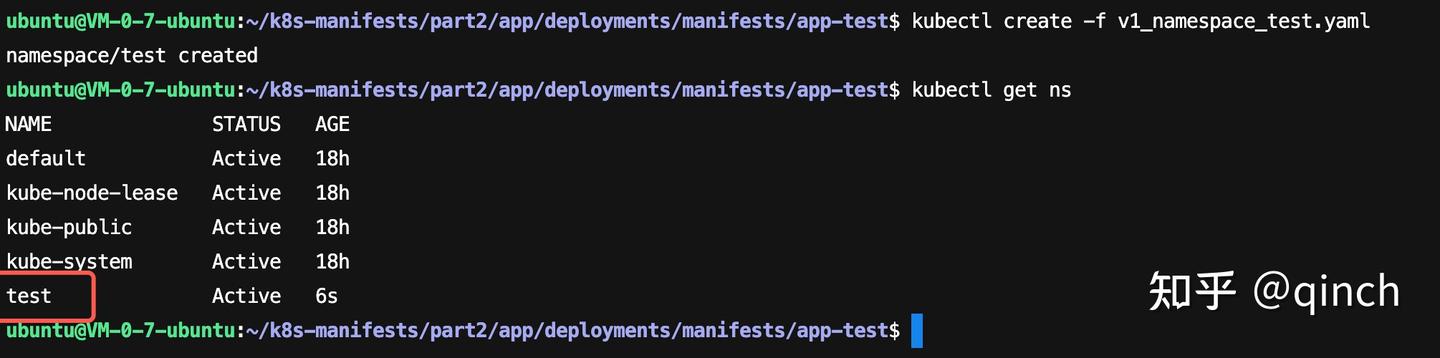
- 在本文中,以test环境和prod环境部署在同一个K8s集群中为例,所以我们需要执行如下命令来分别创建test和prod Namespace:
- kubectl create -f v1_namespace_test.yaml
- kubectl create -f v1_namespace_prod.yaml
- 查看创建的Namespace
3 K8s manifests
- 在app服务中,存在test和prod环境,如果每个环境都需要配置自己的K8s yamls, 其中必然有很多重复的配置。为了简化配置,我们通过kustomize工具来解决多环境k8s yamls配置问题。
- kustomize是一个用来定制K8s配置的工具,可以用于分别管理不同开发环境(比如:dev/test/pre/prod环境)下的K8s yaml。
- kustomize工具引入了Overlay模式:先定义一套通用的基础资源清单(即:Base Layer),再在其上叠加各环境专属的配置变更(即:Patch Layer);该模式类似于类的继承,父类定义公共方法,每个子类可以继承父类的方法,也可以新增自己的方法,也可以对父类中的某个方法进行重新实现。
- Base Layer(也就是app中的deployments/base): Specifies the most common resources
- Patch Layers(也就是app中的overlays): Specifies use case specific resources
- 在app服务中,其相关yaml目录结构如下:
/k8s-manifests/part2/app/deployments # tree
.
├── base // base layer
│ ├── deployment.yaml
│ ├── kustomization.yaml
│ └── service.yaml
├── manifests // kustomize build生成的结构
│ ├── app-prod // 省略展示
│ └── app-test // 测试环境
│ ├── apps_v1_deployment_app.yaml
│ └── v1_service_app.yaml
│ └── v1_namespace_test.yaml
└── overlays // patch layer
├── app-prod // prod环境,省略展示
└── app-test // test环境
├── container_env.yaml
├── container_probe.yaml
├── ns.yaml
└── kustomization.yaml
3.1 环境变量
- 在2.1节中,我们在K8s集群中分别创建了test和prod Namespace, 我们怎么将相关的K8s mainifests在对应的Nameapce中创建?我们可以在deployments/overlays/app-test(Patch Layer)进行显式设置:
cat ./app/deployments/overlays/app-test/kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: test # 显式指定test Namespace
resources:
- ../../base
- ./ns.yaml
patches:
- path: ./container_env.yaml
target:
kind: Deployment
- 现在我们可以在test环境部署app服务了,但是这时候还有个问题:我们的代码在运行的时候,怎么知道自己运行在test还是prod环境中?K8s允许为pod中的每个容器指定自定义的环境变量,所以我们可以通过在deployments/overlays/app-test(Patch Layer)设置环境变量ENV=test,然后在app服务运行的时候,读取ENV环境变量就可以确定自己运行在哪个环境中了。
cat ./app/deployments/overlays/app-test/container_env.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: app
spec:
template:
spec:
containers:
- name: app
env:
- name: ENV # 设置环境变量,在app-prod中则value="prod"
value: "test"
- 登录Pod中的app容器,查看ENV环境变量:
4 应用配置同步
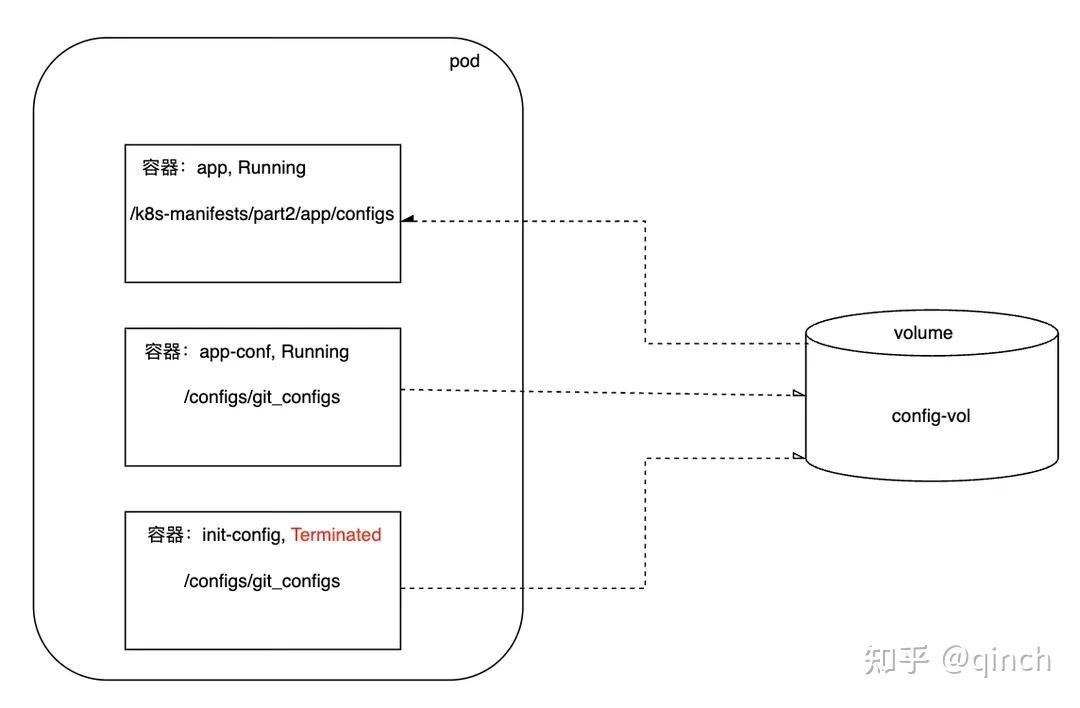
- 几乎所有服务都需要读取配置信息,例如数据库连接地址、端口等参数。这类配置应当与应用二进制文件解耦,不建议将配置硬编码在代码中。在我们的 app 服务中,通过引入 Sidecar 容器(即 app-conf容器,运行 git-sync程序)实现配置同步,并通过 emptyDir 卷将配置文件共享给同一 Pod 内的 app 容器。
4.1 Sidecar容器
- Sidecar容器是与主容器在同一个 Pod 中运行的辅助容器。 Sidecar容器通过提供额外的服务或功能(如日志记录、数据同步等)来增强或扩展主应用容器的功能, 而无需直接修改主应用代码。
- 在我们的app服务中,app-conf容器即为Sidecar容器,app容器即为主容器,app-conf容器通过emptyDir卷将app-conf同步下来的配置文件共享给app容器。这时候有一问题,那么怎么保证app-conf容器在app容器之前启动(如果app容器先启动,那么去读取配置文件,是不存在的)?答案是:init容器。
- app-conf镜像的Dockerfile如下(注:启动命令在K8s的Deployment中):
cat ./app/configs/Dockerfile
FROM registry.k8s.io/git-sync/git-sync:v4.6.0
WORKDIR /configs
COPY ./sparse.txt ./
- K8s Deployment中部分相关配置,如下:
cat ./app/deployments/base/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: app
spec:
template:
metadata:
labels:
app: app
spec:
containers:
# placeholder, 通过kustomize edit set image来注入real image:tag。
- image: mock-image
name: app
imagePullPolicy: IfNotPresent
volumeMounts:
# 名为config-vol的卷挂载在app容器的/k8s-manifests/part2/app/configs目录上
- mountPath: /k8s-manifests/part2/app/configs
name: config-vol
readOnly: true
# placeholder, 通过kustomize edit set image来注入real image:tag。
- image: mock-conf-image # app-conf容器
name: app-conf
imagePullPolicy: IfNotPresent
volumeMounts:
# 名为config-vol的卷挂载在app-conf容器的/configs/git_configs目录上
- mountPath: /configs/git_configs
name: config-vol
command: ["/git-sync"] # app-conf容器的启动命令
args:
- --repo=https://github.com/Qinch/k8s-manifests.git
- --ref=master
- --root=/configs/git_configs
- --link=latest
- --sparse-checkout-file=/configs/sparse.txt
- --depth=1
- --period=60s
# init容器,所有Init容器必须全部执行成功(即:退出码为 0)之后,
# Pod 内的业务容器才会启动。
initContainers:
- name: init-config
# placeholder, 通过kustomize edit set image来注入real image:tag。
image: mock-conf-image
imagePullPolicy: IfNotPresent
volumeMounts:
# 名为config-vol的卷挂载init容器的/configs/git_configs目录上
- mountPath: /configs/git_configs
name: config-vol
command: ["/git-sync"] # init容器的启动命令
args:
- --repo=https://github.com/Qinch/k8s-manifests.git
- --ref=master
- --root=/configs/git_configs
- --link=latest
- --sparse-checkout-file=/configs/sparse.txt
- --depth=1
# 只运行一次,然后退出。如果一直运行,会阻塞后续业务容器的启动。
- --one-time
volumes:
# emptyDir卷没有独立的生命周期,而是和Pod的生命周期关联(
# 即:当Pod删除时,卷就会被删除,卷的内容也就丢失。)
- name: config-vol
emptyDir: {}
- 登陆Pod中app容器查看同步下来的config.yaml
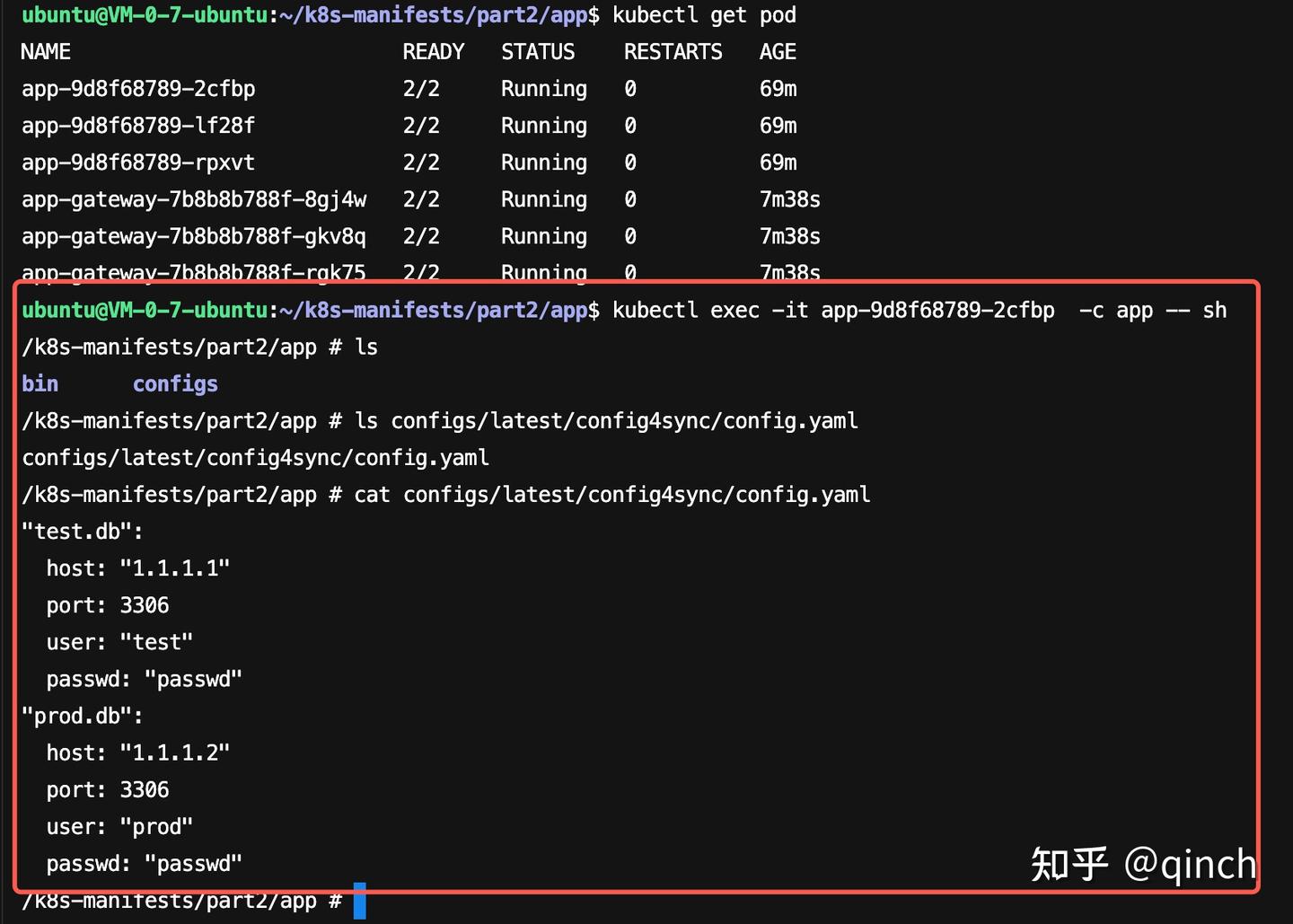
5 容器资源限制
- 同一 K8s 集群通常部署多项业务服务,如果不对 Pod 内容器配置资源限制,容器会无节制消耗 CPU、内存,侵占其他业务资源;同时,K8s 调度器若无法获知 Pod 资源需求(Pod 内所有容器资源需求总和),就无法筛选出满足资源条件的worker node来完成调度。因此需要为 Pod 配置 CPU、内存资源配额requests与limits。
- requests:针对Pod中的容器单独指定(Pod中所有的容器requests之和即为该Pod的requests),指定了Pod对资源需求的最小值,K8s会利用该信息决定将 Pod 调度到哪个节点上(即:worker node上可分配资源量是否满足Pod的requests),它代表容器对资源需求的最小值(注:某个worker node是否满足该Pod的request,并不是根据此时的worker node是资源实际使用量, 而是根据worker node的可分配资源量= worker node上节点总可分配资源 减去 已经部署的所有Pod的request之和,来判断是否满足该Pod的requests)。
- limits:针对Pod中的容器单独指定(Pod中所有的容器limits之和即为该Pod的limits),用于保证运行的容器不会使用超出所设限制的资源,也就是容器可以消耗的最大量。
- 我们以app服务为例,其CPU/内存的requests和limits如下:
at ./app/deployments/overlays/app-test/container_resources.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: app
spec:
template:
spec:
containers:
- name: app
resources:
requests: # app容器的资源请求量
cpu: 500m
memory: 128Mi
limits: # app容器的资源limits
cpu: 1
memory: 256Mi
6 Pod健康检查
- 在上篇2.1节提到,Pod的生命周期是短暂的,其生命周期可能因调度、故障或升级而随时终止。那么我们怎么判断一个Pod是否就绪(可以接受业务请求)?是否存活(是否需要重启容器)?答案就是Readiness Probe和Liveness Probe。
- Startup Probe:
- Startup Probe(即:启动探针, 可以为Pod中的每个容器分别设置启动探针):指示容器中的应用是否已经启动。如果提供了启动探针,则在启动探针探测成功之前不会执行ReadinessProbe和LivenessProbe,直到此探针成功ReadinessProbe和LivenessProbe才会运行。如果启动探针探测失败,K8s将重启容器。 如果容器没有提供启动探测,则默认状态为Success。
- Readiness Probe:
- Readiness Probe(即:就绪探针,可以为Pod中的每个容器分别设置就绪探针):用于周期性的检查容器是否准备就绪,如果某个pod没有准备就绪,则会从Service中删除该pod, 如果pod再次准备就绪,则重新将该pod添加到Service;换句话说也就是,就绪探针决定了容器什么时候就绪,可以接受业务请求。
- Liveness Probe:
- Liveness Probe(即: 存活探针,可以为Pod中的每个容器分别设置存活探针):用于周期性的检查容器是否还在运行,如果探测失败,k8s将重启容器(容器重启过程中 Pod 会变为 NotReady,自动从 Service 摘除流,容器重启成功并通过 Readiness Probe探测后,Pod 恢复 Ready,重新接入 Service);换句话说也就是,存活探针决定了何时重启容器(重启容器:创建一个新的容器,而不是重启原来的容器)。
- 我们以app服务为例,来看一下以上探针的配置(需要指出的是,StartupProbe探测成功之后,就会停止探测,但是LivenessProbe和ReadinessProbe则会一直周期性探测):
cat app/deployments/overlays/app-test/container_probe.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: app
spec:
template:
spec:
containers:
- name: app # app容器的健康检查
startupProbe: # 启动探针
httpGet:
path: /health
port: 8080
periodSeconds: 5 # 每5秒检查一次
failureThreshold: 10 # 最多失败10次
successThreshold: 1 # 1次成功即通过
livenessProbe: # 存活探针
httpGet:
path: /health
port: 8080
periodSeconds: 10 # 每10秒检查一次
failureThreshold: 3 # 最多失败3次
successThreshold: 1
readinessProbe: # 就绪探针
httpGet:
path: /health
port: 8080
periodSeconds: 5
failureThreshold: 2
successThreshold: 1
7 Service服务访问
- 在前面的章节,我们以 Demo 项目 app 服务为例,介绍了服务构建、K8s 清单、Sidecar 容器、Pod 健康探针;本节开始讲解 app-gateway 基于 gRPC 调用 app 服务、对外提供 HTTP 接口的实现(在上篇5.2节介绍了为什么需要Service,本文不再重复介绍),请求链路如下图所示:
- 外部访问 → app-gateway(转发) → app服务(业务) 图7-1
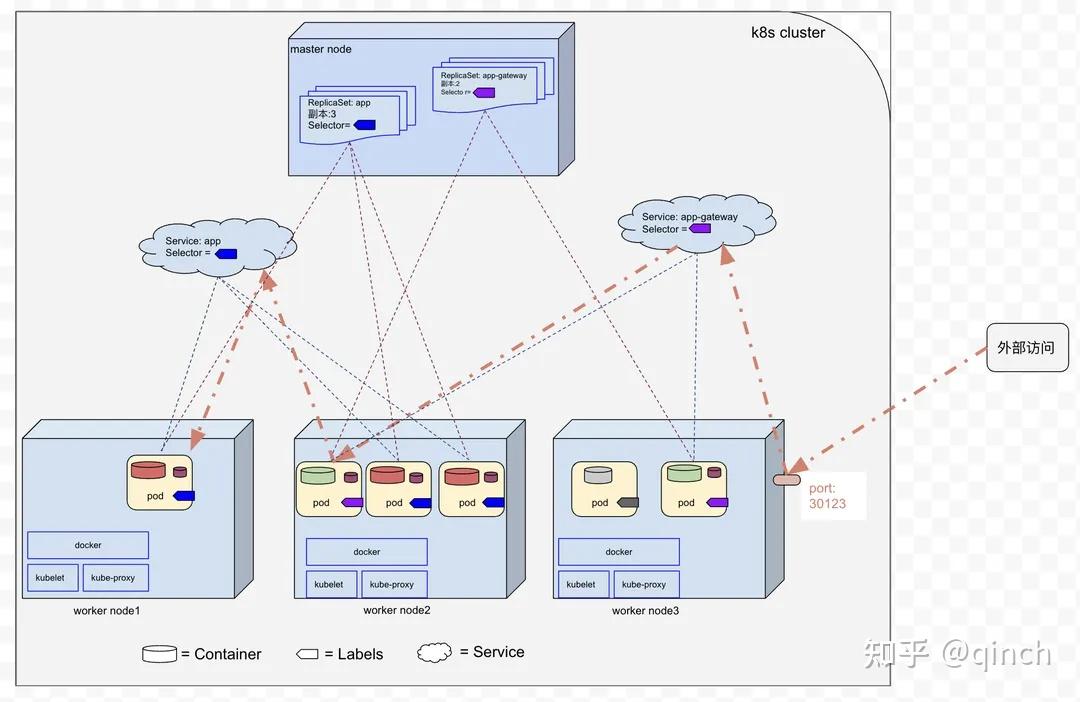{kind=link}
7.1 集群内部app-gateway服务访问app服务
- app-gateway服务调用app服务属于集群内部Pod间的通信,所以app服务需要创建Service的类型为ClusterIP:
cat ./app/deployments/base/service.yaml
apiVersion: v1
kind: Service
metadata:
name: app
spec:
type: ClusterIP # Service类型
ports:
- port: 80 # # 该Service的HTTP监听端口
targetPort: 8080
- port: 50051 # 该Service的gRPC监听端口
targetPort: 50051
selector:
app: app
- 在我们的app-gateway代码中通过Service名称(FQDN,即app.test.svc.cluster.local:50051)来访问app服务。
7.2 集群外部访问app-gateway服务
- app-gateway服务队集群外部提供服务,属于集群内部Pod暴露给集群外部客户端。在我们的demo中给app-gateway服务创建一个NodePort类型的Service。
apiVersion: v1
kind: Service
metadata:
name: app-gateway
spec:
type: NodePort # Service类型
ports:
- port: 80 # ClusterIP的端口号
targetPort: 8080
# 指定worker node的端口号,通过worker node的30123端口可以访问该Service
nodePort: 30123
selector:
app: app-gateway
8 Pod优雅终止
- Pre-stop 钩子是 K8s 提供的在容器被正式终止前执行的一段自定义逻辑。当 Pod 中一个容器需要终止运行的时候,Kubelet 在配置了 Pre-stop 钩子时会立即执行这个停止前钩子,并且仅在执行完钩子程序之后,才会向容器进程发送 SIGTERM 信号;程序代码中捕捉到 SIGTERM 信号后,可执行关闭外部连接等优雅退出处理。
- Pod 删除过程如下:
- 1 Pod 被删除,状态被设置为 Terminating。
- 2 Endpoint 控制器 将 Pod 从 Service 的 Endpoint 列表中摘除(新流量不再纳入调度);kube-proxy 异步监听 Endpoint 变化,更新节点转发规则(注意:本网络更新流程(步骤2),与后续容器终止流程(步骤3/4)是并行的)。
- 3 如果 Pod 设置了 Pre-stop 钩子,则执行该Pre-stop钩子,然后等待它执行完毕(terminationGracePeriodSeconds开始计时)。
- 4 Kubelet 向 Pod 中的各个容器发送 SIGTERM 信号,通知容器进程开始优雅停止。
- 5 等待容器进程完全停止;如果在 terminationGracePeriodSeconds(终止宽限期)内进程未退出,Kubelet 会发送 SIGKILL 信号强制杀死进程。
- 6 所有容器进程终止后,Kubelet 清理 Pod 资源。
- 在 Pod 删除过程中,因为网络规则同步(kube-proxy) 和容器终止流程是并行的,会存在:Endpoint 已摘除,但外部网关还没同步完成,仍有流量转发到即将停止的 Pod 上,导致请求被拒绝。 所以我们可以在 Pre-stop 钩子中执行 sleep 等待几秒,等待网络规则完全同步后,再发送 SIGTERM 停止容器,避免请求报错。
- app服务中,Prs-stop钩子设置如下:
cat ./app/deployments/overlays/app-test/container_lifecycle.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: app
spec:
template:
spec:
terminationGracePeriodSeconds: 60
containers:
- name: app
lifecycle:
preStop:
exec:
command:
- sh
- c
- "sleep 30"
9 附录
- Demo项目具体的执行过程请查看 https://github.com/Qinch/k8s-manifests/tree/master 的README。
10 参考资料
- Kubernetes in Action》
- https://kubernetes.io/zh-cn/docs/concepts/overview/