kubernetes快速入门
1 简介
1.1, 虚拟机和容器的区别
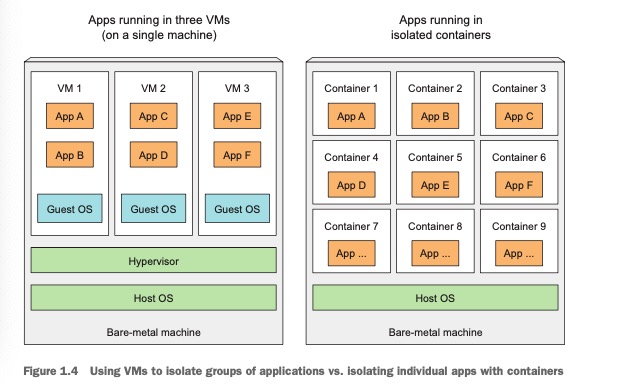
每个虚拟机运行在自己的Linux内核上(即下图中Guest OS, 每个VM可以安装不同版本的linux系统),而容器都是调用同一个宿主机内核(如果一个容器化的应用需要一个特定的内核版本,那么它可能不能再每台机器上工作,也不能将一个x86架构编译的应用容器化之后,又期望他在arm架构的机器上运行)。
1.2 容器技术和docker的关系
- docker是容器技术的一个分支,rkt也是一个运行容器的平台,可以作为docker的替代方案。
1.3 什么是k8s
百度百科中k8s的定义:
-
kubernetes,简称K8s,是用8代替名字中间的8个字符“ubernete”而成的缩写。
-
k8s是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的一种机制。
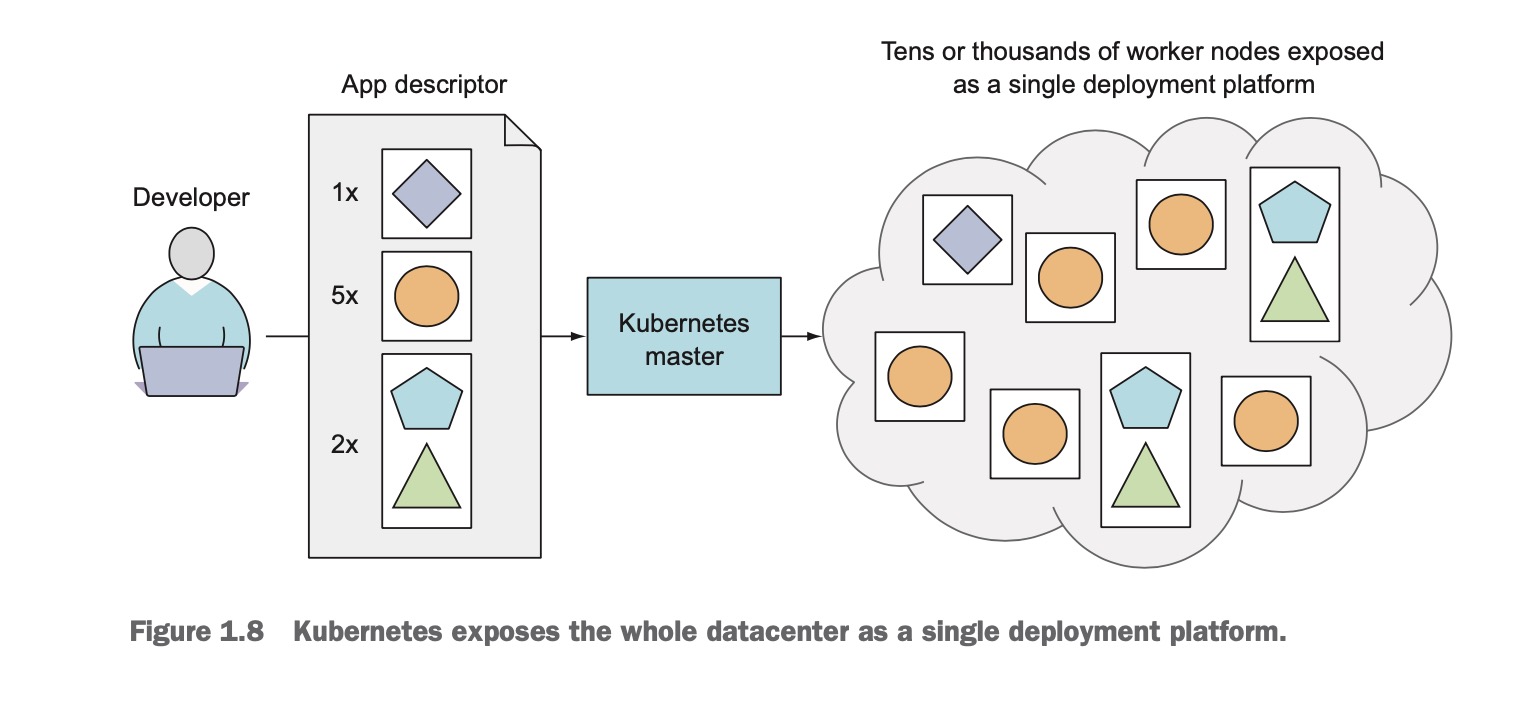
一个简单的k8s系统如下图所示,由一个master node 和 任意数量的worker node. 当开发提交app 描述文件(比如描述运行多少个副本,暴露端口,指定的镜像,探活, 更新策略等)到master节点,然后k8s把app部署到worker nodes. 至于app部署到哪个woker node, 我们并不关心。
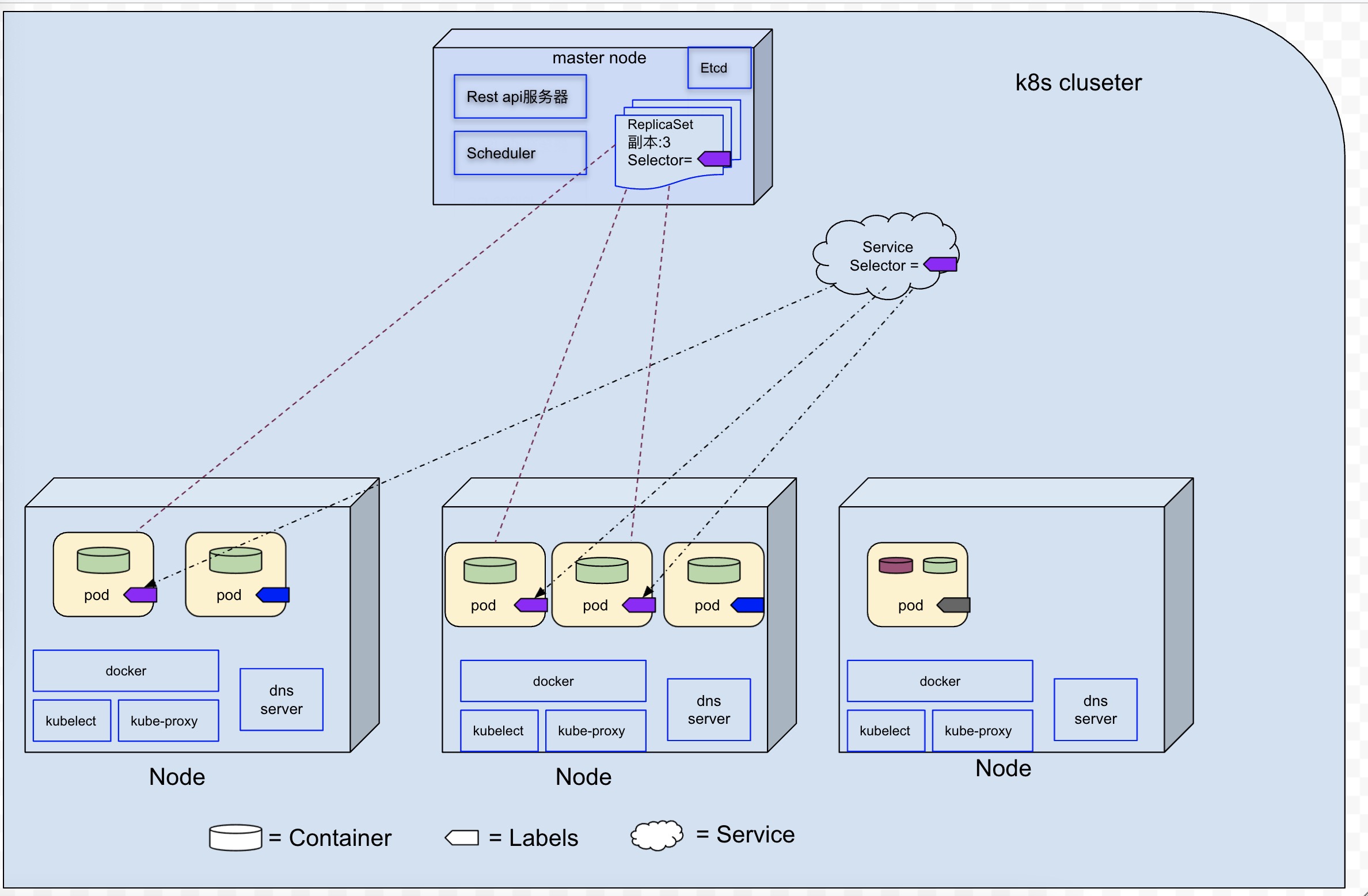
一个更详细的k8s系统如下图所示(该图链接), 该k8s cluster, 由一个master node和3个worker node组成。
1.4 k8s和docker的关系
- docker是k8s最初唯一支持的容器类型,但是现在k8s也开始支持rkt以及其他的容器类型,不应该错误的认为k8s是一个专门为docker容器设计的容器编排系统。
1.5 为什么多个容器比单个容器中包含多个进程要好
容器之所以被设计为单个容器只运行一个进行(除非进程本身产生子进程),是因为如果单个容器中运行多个不相关的进程,那么开发人员需要保持这些所有进程都运行OK, 并且管理他们的日志等(比如,两个进程,其中一个生产者进程,一个消费者进程,如果消费者进程crash之后,我们需要考虑该进程重启的机制)。
2, 创建一个docker镜像
在安装好docker环境之后,我们可以创建一个node.js应用,该应用收http请求,并响应运行的主机名。
app.js内容如下:
const http = require('http');
const os = require('os');
console.log("Kubia server starting...");
var handler = function(request, response) {
console.log("Received request from " + request.connection.remoteAddress);
response.writeHead(200);
response.end("This is v1 running in pod " + os.hostname() + "\n");
};
var www = http.createServer(handler);
www.listen(8080);
Dockerfile的内容如下
FROM node:7
ADD app.js /app.js
ENTRYPOINT ["node", "app.js"]
app.js和Dockerfile的目录结构如下:
- image:
- app.js
- Dockerfile
-
创建一个名为
allen的镜像 -
cd ./image -
docker build -t allen .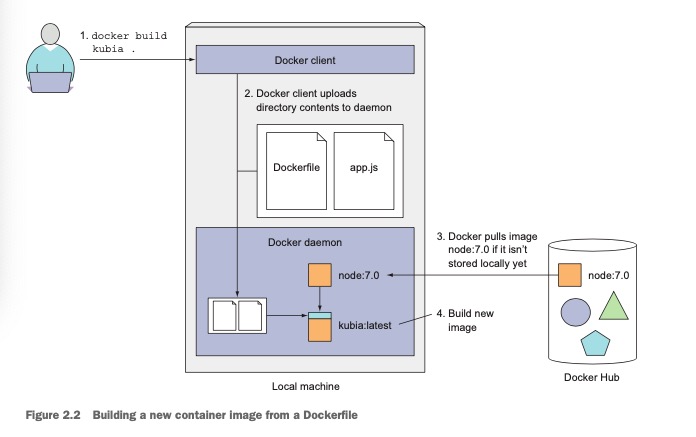
-
将该镜像推送到镜像仓库(docker hub)
-
docker tag allen qinchaowhut/allen:v1 -
docker push qinchaowhut/allen:v1 -
运行
allen镜像 -
docker run --name allen-container -p 8080:8080 -d qinchaowhut/allen:v1 -
curl http://localhost:8080

到此介绍了容器/k8s相关的基础知识,接下来详细介绍k8s中的相关概念。
2 Pods
2.1 为什么需要pod
前边已经提到,容器被设计为每个容器只运行一个进程,那么多个进程就不能聚集在一个单独的容器,但是容器之间是彼此完全隔离的,多个进程分布在对应的多个容器中,进程之间无法做到资源共享(比如,前边提到到生产者/消费进程,他们通过共享内存和信号量来通信,但是如果生产者进程和消费者进程分布在两个容器中,则IPC是相互隔离的,导致无法通信)。所以我们需要一种更高级的结构来将容器绑定在一起,并且将它们作为一个单元进行管理(即:多个容器间共享某些资源),这就是为什么需要pod的根本原理。
2.2 了解pod
- pod是k8s中的基本的部署单元,在worker nodes之间进行调度。
- 可以把pod看作一个独立的机器,一个pod中可以运行一个或者多个容器,这些容器之间共享相同的ip和port空间。
- 一个pod的所有容器都运行在同一个woker node中,一个pod不会跨越两个worker node.
- 由于大多数容器的文件系统来自于容器镜像,所以每个容器的文件系统与其他容器是完全隔离的,但是可以试用Volume在容器间共享文件目录。
- pod是短暂的, 他们随时的会启动或者关闭。也就是这如果某个pod被销毁之后,重新创建的pod的ip可能会变化。
2.3 创建一个pod
我们从docker hub商找了个一个dns相关的镜像(即tutum/dnsutils),来创建一个pod, 对应的dnsutils.yaml如下
apiVersion: v1
kind: Pod
metadata:
name: dnsutil-pod
spec:
containers:
- image: tutum/dnsutils
name: dnsutil
command: ["sleep", "infinity"]
kubectl create -f dnsutils.yaml
3 Lables
标签是一个可以附加到资源的任意key-value对(一个标签就是一个key/value对,每个资源可以拥有多个标签), 然后通过Selector(即标签选择器)来选择具有确切标签的资源。
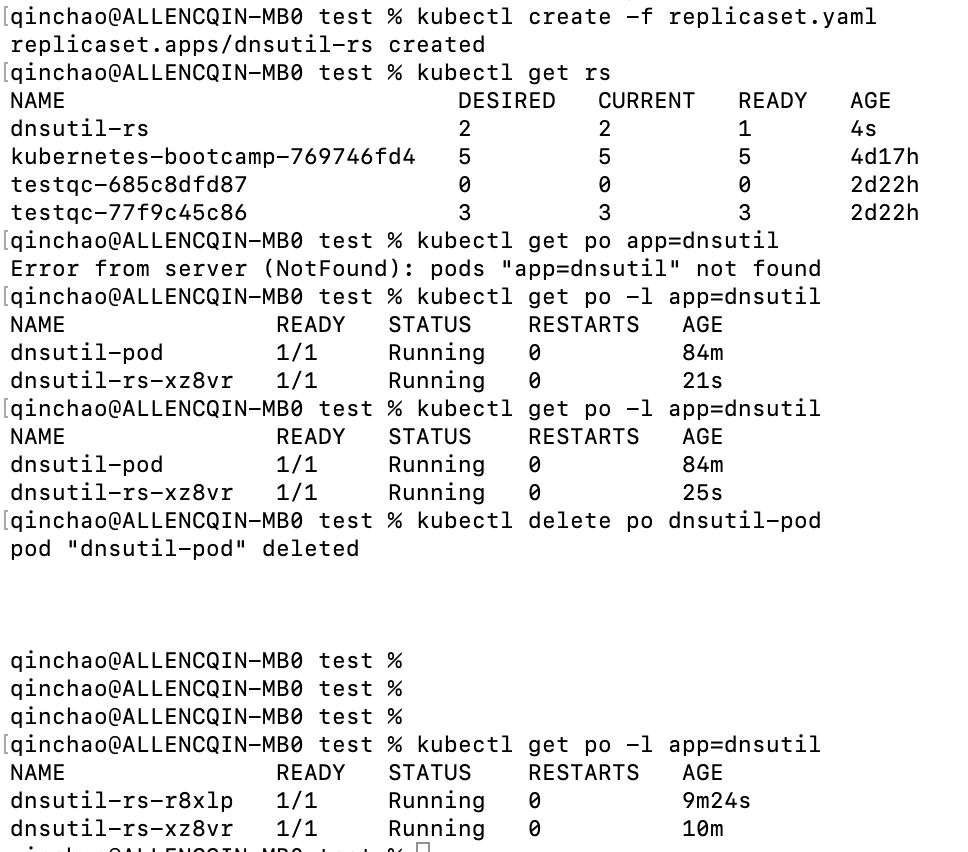
在之前创建的dnsutil-pod添加标签app=dnsutil,然后通过kubectl get 命令行查看标签为app=dnsutil的pod
kubectl label po dnsutil-pod app=dnsutilkubectl get po -l app=dnsutil
4 ReplicaSet
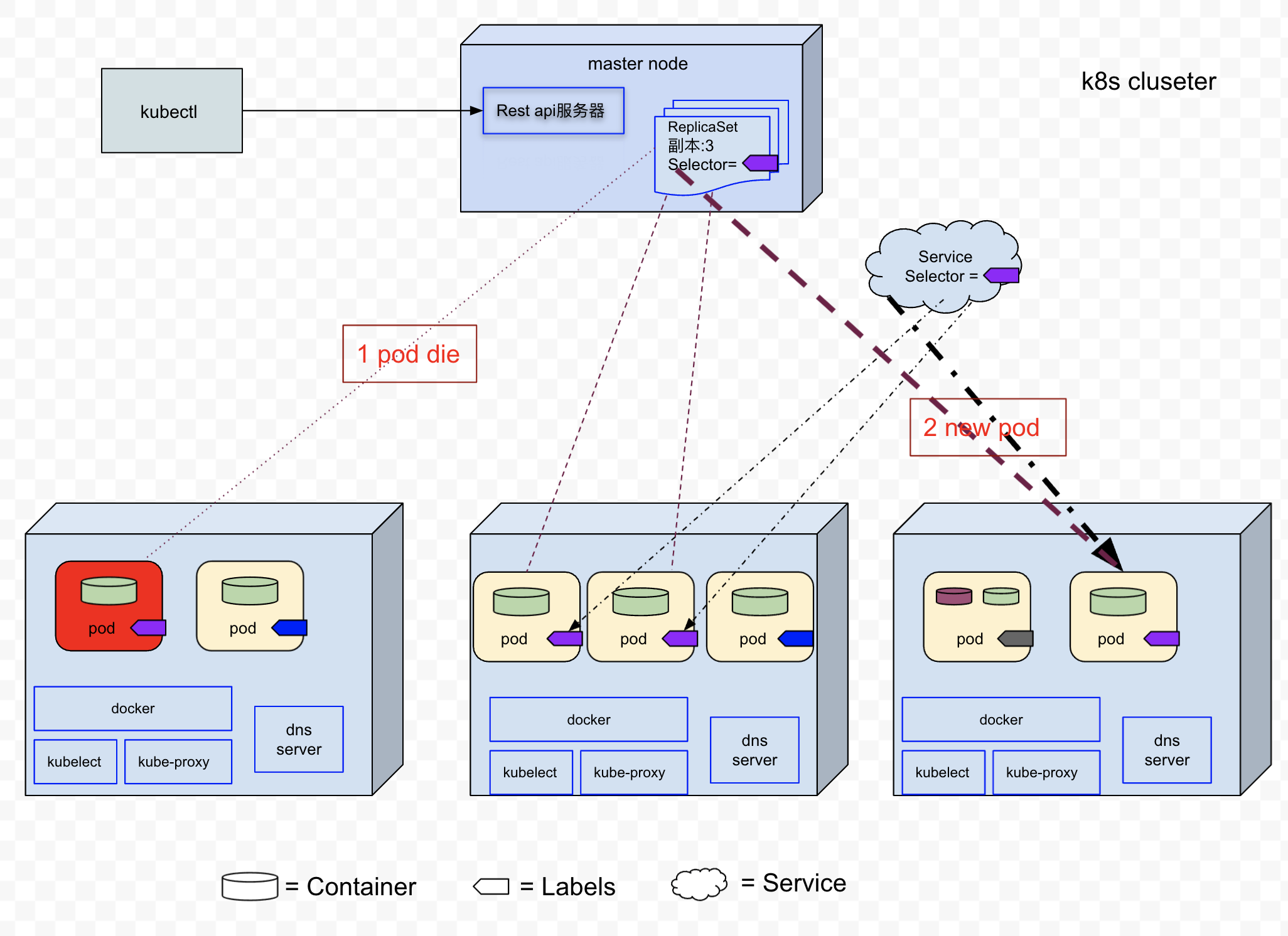
前边我们通过手工创建了dnsutil-pod, 如果dsnutils-pod由于worker node节点失败, 那么该pod也会消失,并且不会被新的替换。或者如果我们想创建n个dnsutil-pod,只能通过手工创建吗?答案是:ReplicaSet(即副本控制器)
ReplicaSet是一种k8s资源,通过它可以保持pod始终按照期望的副本数量运行。如果某个pod因为任何原因消失,则ReplicaSet会注意到缺少了的pod,并且创建新的pod替代它。ReplicaSet是一种期望式声明方式,我们只需要告诉它我期望的副本数量,而不用告诉它怎么做。
4.1 创建一个ReplicaSet
replicaset.yaml文件内容如下:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: dnsutil-rs
spec:
replicas: 2
selector:
matchLabels:
app: dnsutil
template:
metadata:
labels:
app: dnsutil
spec:
containers:
- name: dnsutil
image: tutum/dnsutils
command: ["sleep", "infinity"]
5 Services
5.1 为什么需要服务
- pod是短暂的, 随时都可能被销毁。
- 新的pod创建之前不能确定该pod分配的ip
- 水平伸缩也就以为着多个pod可能提供相同的服务,客户端不想也不关心每个pod的ip, 相反,客户端期望通过一个单一的ip地址进行访问多个pod.
服务是一种为一组功能相同的pod提供单一不变的接入点的资源。当服务存在时,该服务的ip地址和端口(创建服务的时候,通过ports[n].port和ports[n].targetPort 指定了服务端口到pod端口的映射)不会改变。客户端通过ip和port与服务建立连接,然后这些连接会被路由到提供该服务的某个pod上(通过负载均衡)。
5.2 集群内部pod间通信
服务的后端可能不止有一个pod, 服务通过标签选择器来指定哪些pod属于同一个组,然后连接到服务的客户端连接,服务会通过负载均衡路由到某个后端pod.
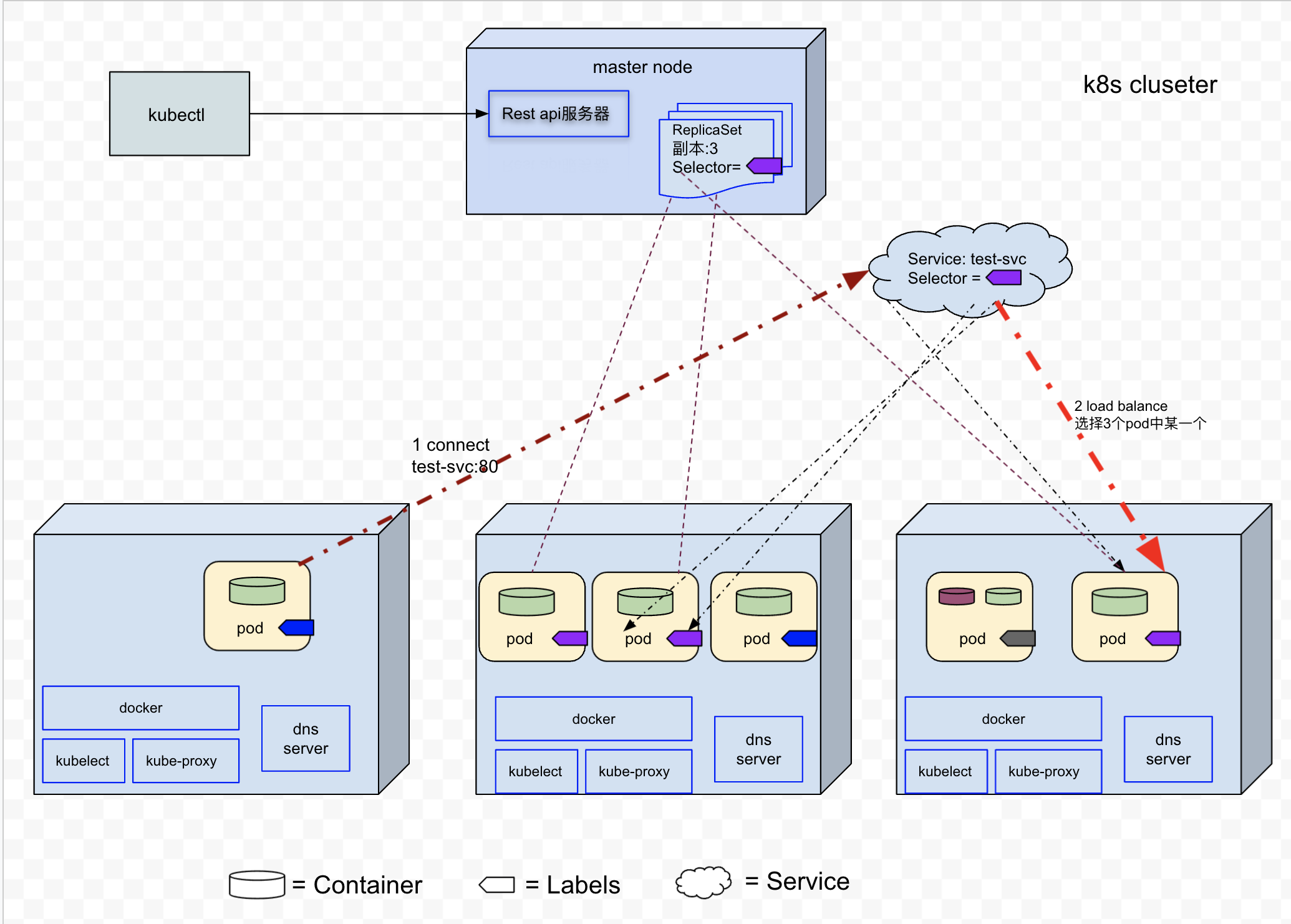
在测试环境,我们创建一个服务,svc.yaml文件对应的内容为:
apiVersion: v1
kind: Service
metadata:
name: test-svc
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: testing
同时创建一个ReplicaSet,其中容器运行我们的nodejs应用程序(前边创建的allen镜像) replicaset-fqdn.yaml, 该文件内容如下:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: test-fqdn
spec:
replicas: 3
selector:
matchLabels:
app: testing
template:
metadata:
labels:
app: testing
spec:
containers:
- name: nodejs
image: qinchaowhut/allen:v1
5.2.1 服务发现
在k8s集群内部,创建了服务之后,不需要查询服务的Cluster iP, 然后在把Cluster IP配置给客户端pod。 客户端pod可以通过DNS发现之前创建的服务。
每个服务在k8s集群内部的DNS server中都会存在一个条目,客户端pod可以通过服务名称来访问服务(FQDN)。
在前边的例子中,我们创建test-svc服务, 然后登录之前创建dnsutils pod中的容器, 可以通过通过nslookup查看test-svc.default.svc.cluster.local域名对应的ip(即test-svc的Cluster ip)
需要指出的是: Cluseter IP是ping不通的,应为这个Cluseter IP一个虚拟IP, 只有与服务端口结合时才有意义。
由于都在同一明命名空间,我们可以在dnsutils容器中执行nslookup testsvc,查看服务的Cluster IP
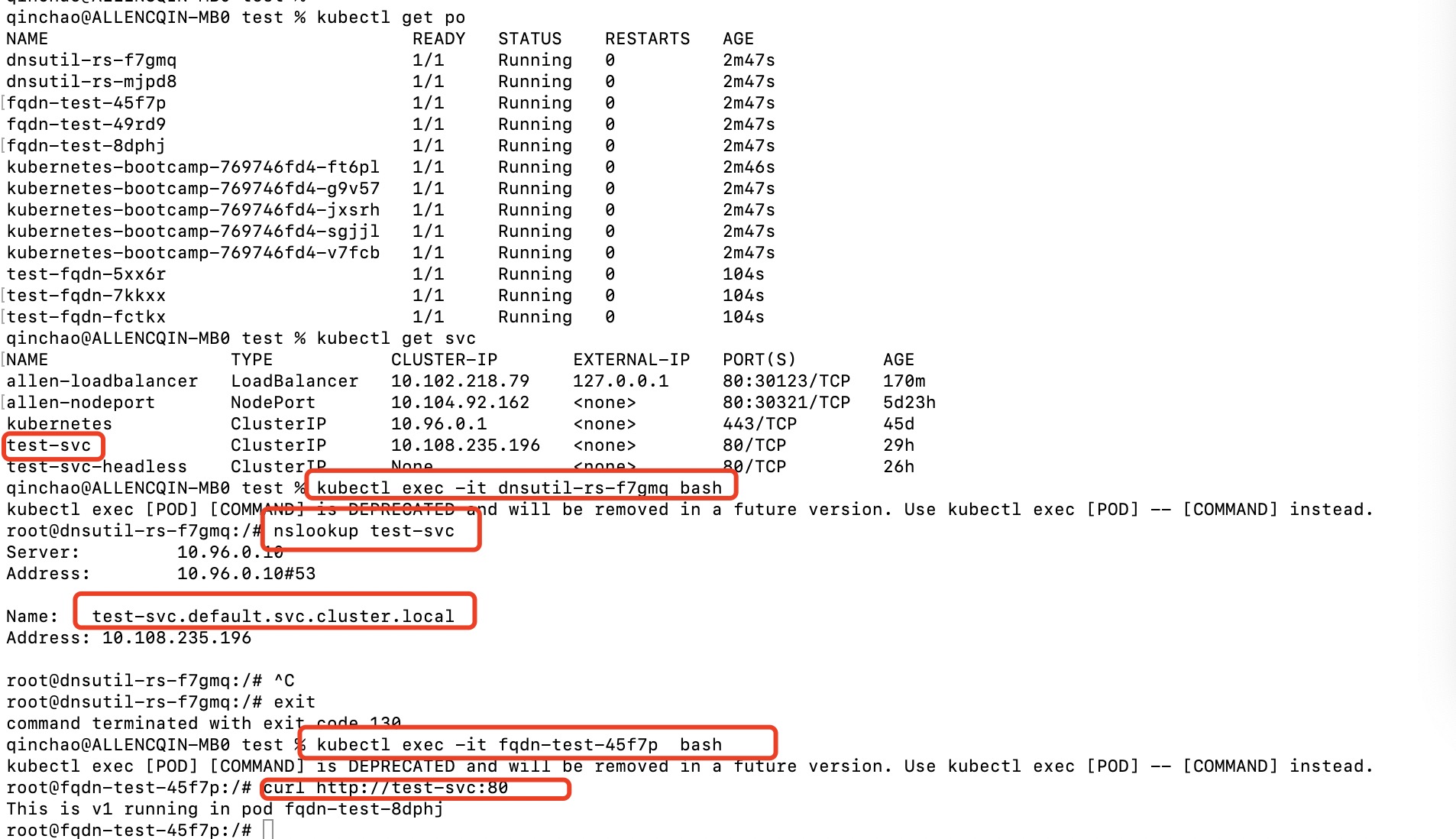
5.3 集群内部服务暴露给外部客户端
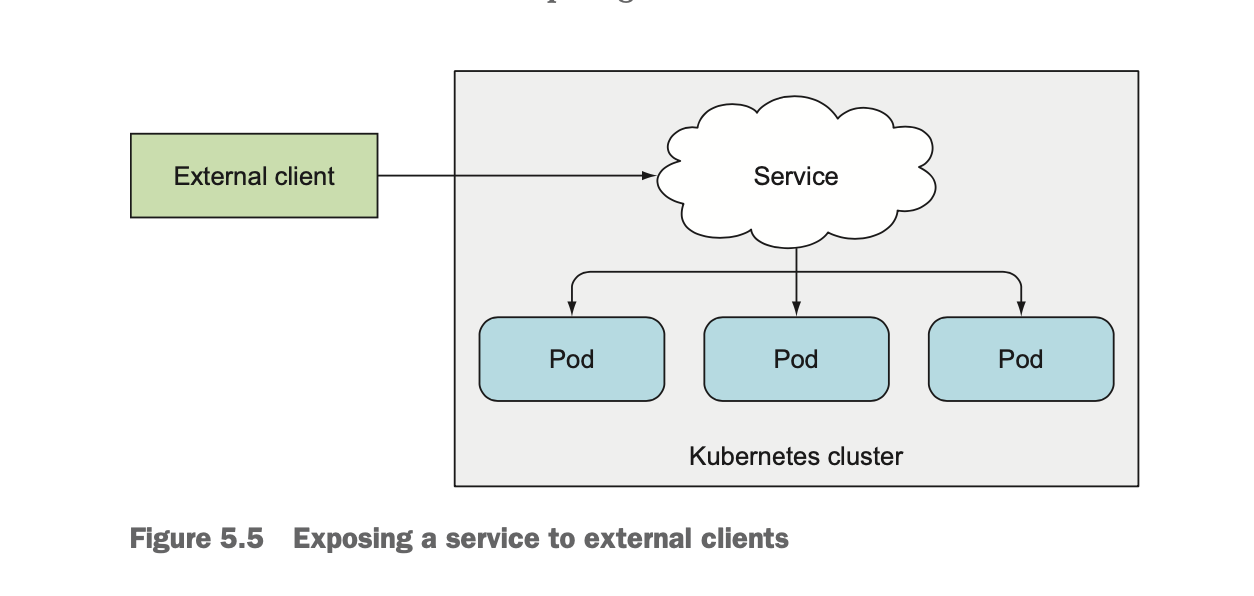
如上图所示,如果集群外部客户端需要访问集群内部的服务,则可以通过如下几种方式:
- NodePort类型服务
- LoadBalancer类型服务
- 通过Ingress暴露服务(通过一个IP地址公开多个服务)
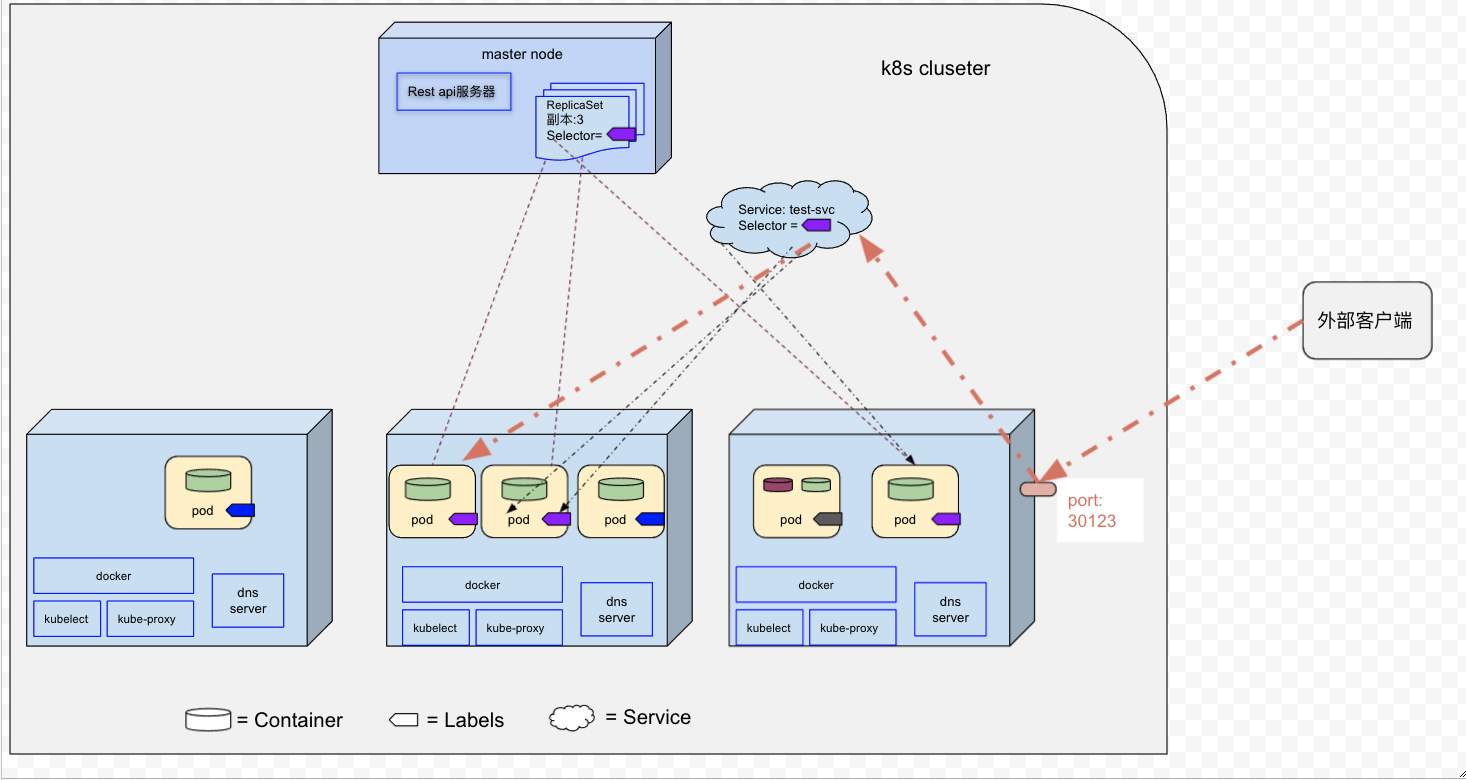
1,NodePort类型服务
通过创建NodePort类型服务,可以让k8s在所有的worker节点上保留一个端口(所有节点都是使用相同的端口号),并将传入的连接转发给属于该服务的pod.
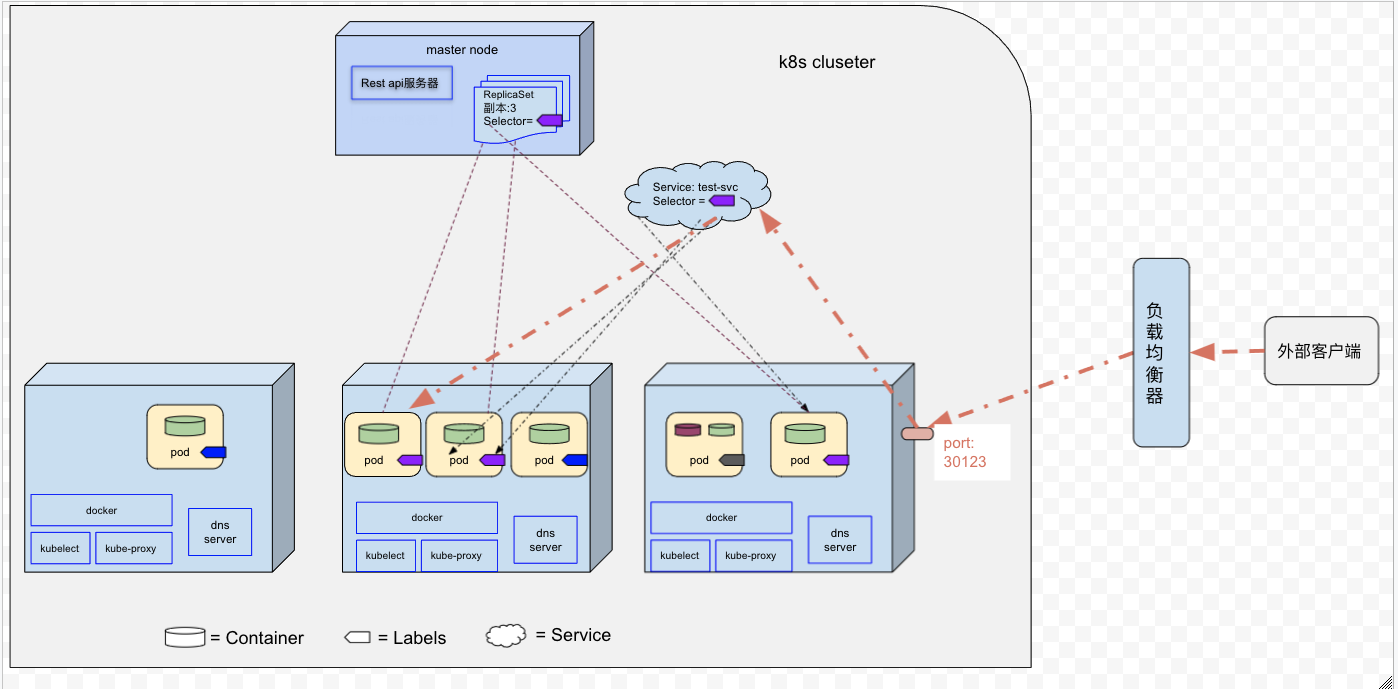
2, LoadBalancer类型服务
LoadBalancer服务是NodePort服务的一种扩展。客户端通过一个专用的负载均衡器来访问服务(客户端通过负载均衡器的IP连接到服务)。其中负载均衡器将流量重定向到worker node的节点端口。
5.4 pod连接集群外的服务
略
5.5 使用headless服务来发现独立的pod
集群内部pod间也可以通过headless进行通信。headless服务,即在创建服务的spec中将cluseterIP字段设置为NONE。 当通过DNS服务器查询headless服务名称的时候,DNS服务器返回的是所有pod IP,而不是单个服务的IP. 客户端pod可以通过这些IP连接到其中一个,多个或者全部的pod.
5.6.1创建一个headless服务
apiVersion: v1
kind: Service
metadata:
name: test-svc-headless
spec:
clusterIP: None
ports:
- port: 80
targetPort: 8080
selector:
app: testing

通过nslookup查询test-svc-headless服务

6 Deployment
Deployment用于部署应用程序,并且用声明的方式升级应用程序。其中,Deployment由ReplicaSet(1:N)组成,并且由ReplicaSet来创建和管理Pod

6.1, Deployment的升级策略
a, RollingUpdate, 即滚动更新(默认的升级策略),该策略会渐进的删除旧的pod,同时创建新的pod, 是应用程序在整个升级过程中都处于可用状态。(注意:在升级过程中,pod的数量可以在期望的副本数量左右浮动,该上限和下限是可以设置的)
b, Recreate, 即一次性删除所有的Pod, 然后才创建新的Pod(缺点:存在服务中断的情况)
需要指出的是升级完成之后,旧的ReplicaSet仍然保留(用于回滚,即升级的逆过程)
在测试环境,滚动更新的yaml文件内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: testqc
spec:
replicas: 3
template:
metadata:
name: allen
labels:
app: testing
spec:
containers:
- image: qinchaowhut/allen:v1
name: nodejs
imagePullPolicy: IfNotPresent
selector:
matchLabels:
app: testing
- run
kubectl create -f deployment-v1yaml --record
其中record参数用于记录历史版本号,在查看升级history,显示CHANGE-CAUSE.
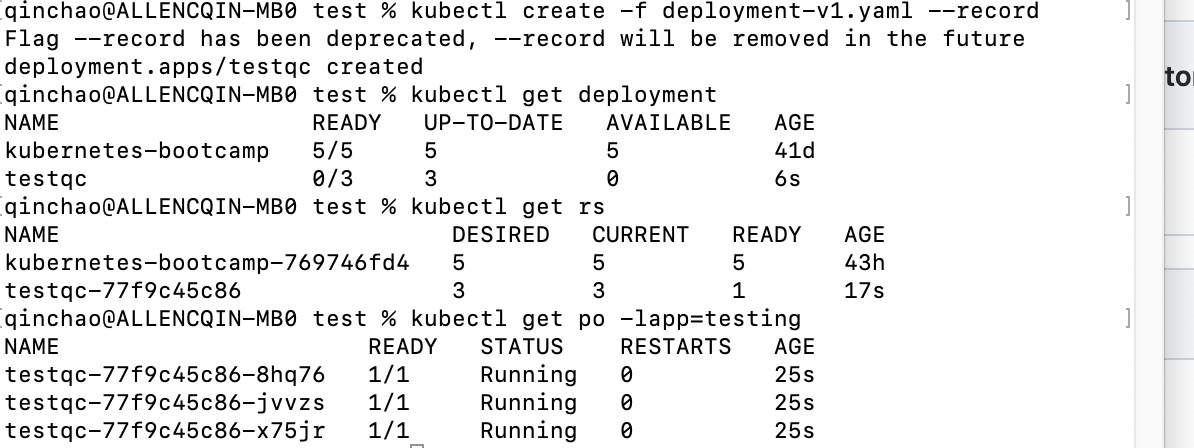
apiVersion: v1
kind: Service
metadata:
name: allen-loadbalancer
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 8080
selector:
app: testing
-
run
kubectl create -f svc-loadbalancer.yaml
-
run
curl http://127.0.0.1:80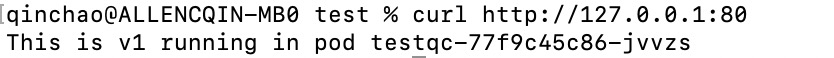
6.2, 触发升级
触发条件:只要修改deployment中定义的pod模板,k8s就会自动将实际的系统状态收敛为资源中定义的状态。
可以通过修改Deployment中pod模板的镜像,来触发升级。
- 通过
kubectl set image deployment testqc nodejs=qinchaowhut/allen:v2来修改Deployment的pod模板内的镜像(其中deployment的name为testqc, nodejs为容器name, qinchaowhut/allen:v2为镜像版本)
升级完成之后,发送curl请求:
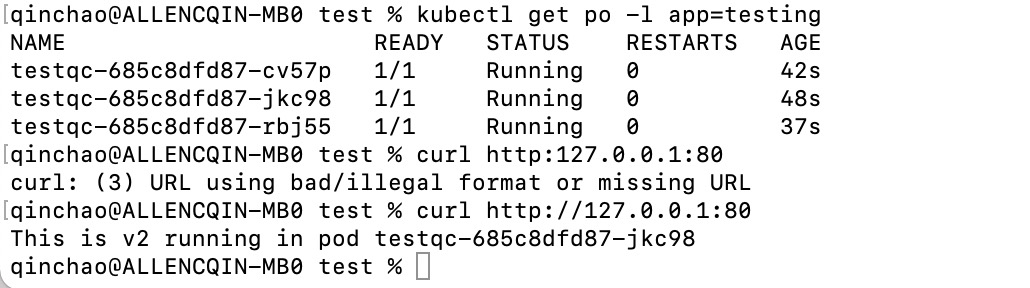
-
查看升级前后ReplicaSet
 通过上图, 可以看出旧的rs仍然本保留
通过上图, 可以看出旧的rs仍然本保留 -
kubectl rollout status deployment testqc
-
可以观察整个升级过程
6.3, 回滚
Deployment始终保持着升级后的版本历史记录,其中历史版本号会被保存在ReplicaSet中。 由于滚动升级成功之后,不会删除老版本的ReplicaSet,这使得可以回滚到任意一个历史版本(注意,如果手工删除ReplicaSet, 便会丢失Deployement的历史版本,而导致无法回滚)。
kubectl rollout undo deployment testqc- 回滚到上一个版本
kubectl rollout history deployment testqc- 查看升级历史
kubectl rollout undo deployment testqc --to-revision=1- 回滚到第一个版本

6.4, 控制滚动升级速率
在Deployment的滚动升级期间,maxSurge和maxUnavaliable这两个属性会决定一次替换多少个pod(可以通过rollingUpdate的子属性来配置,maxSurge和maxUnavailable可以设置成百分数或者绝对值)
-
maxSurge:表示除了Deployment中配置的期望副本数之外,最多允许超出的pod的数量。默认值为25%.(如果期望副本数设置为4,那么滚动升级过程中,不会运行超过5个pod).
需要注意的是:When converting a percentage to an absolute number, the number is rounded up. -
maxUnavailable:表示滚动升级过程中,相对于期望副本数,允许有多少个pod实例可以处于不可用状态,默认值25%.(如果期望副本数量为4,那么整个发布过程中,只能有一个pod处于不可用状态)
需要注意的是:When converting a percentage to an absolute number , the number is rouded down. -
在我们测试环境中,Deployment设置的期望副本数量为3,所以maxSurge为1, maxUnavailable 是0, 则整个升级过程如下:
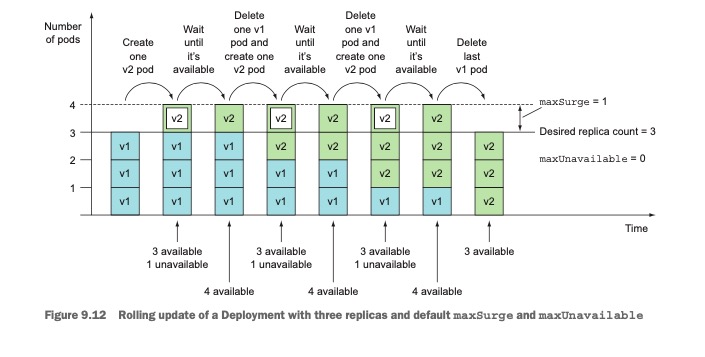
-
假设我们配置的期望副本数量仍然为3,但是maxSurge和maxUnavailable都是1,则整个发布过程如下(
需要注意的是:maxUnavailable是相对于期望副本数而言的, 即maxUnavailable设置为1,但是整个更新过程中,不可用pod数量可以超过1个):
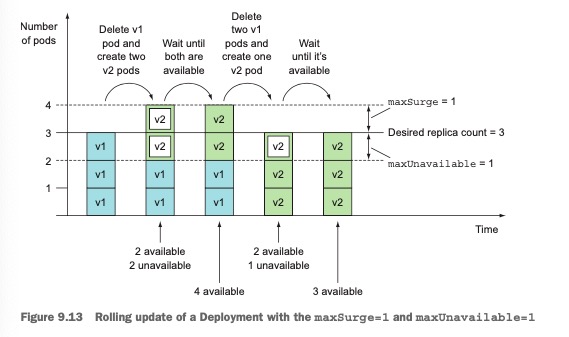
6.5, 暂停/恢复滚动升级
在某次版本发布过程中,可能我们并不想滚动升级所有的pod, 而是在滚动升级过程中,先升级一小部分pod, 然后暂停升级过程。通过查看这一小部分用户请求的处理情况,如果符合预期,就可以用新的pod替换所有旧的pod.(金丝雀发布:是一种可以将应用程序的出错版本和其影响到的用户的风险化为最小的计数。与其直接向每个用户发布新版本,不如用新版本替换一个或者一小部分的pod。)
在通过kubectl set image命令触发滚动更新之后,立马执行如下命令,暂停滚动更新:
kubectl rollout pause deploymnet testqc
一旦确认新版本能够正常工作,就可以恢复滚动升级,用新版本pod替换所有旧版本的pod
kubectl rollout resume deployment testqc
需要指出的是,在滚动升级过程中,想要在一个确切的位置暂停滚动升级目前无法做到。
6.6, 阻止出错版本的滚动升级
minReadySeconds:指定新创建的pod至少要成功运行多久之后,才能将其视为可用。在pod尅用之前,滚动升级的过程不会继续。
7,附录
- YAML文件可以包含多种资源定义,YAML manifest可以使用包含三个横杠(—)的行来分隔多个对象。
- 相关的yaml见 https://github.com/Qinch/k8s-in-action-test
8,参考资料
- 《k8s in action》
- Learn the Kubernetes Key Concepts in 10 Minutes